












Von Marcus Hartmann, Felix Baumann, Maria Foelster und Joshua Wenn. Daten sind der grundlegende Baustein im Bereich der künstlichen Intelligenz (KI), da sie das Potenzial für Innovation bieten und es der generativen KI (GenAI) ermöglichen, ihre Fähigkeiten zu entfalten. GenAI, ein faszinierender Bereich innerhalb des weiten Feldes der künstlichen Intelligenz, konzentriert sich auf maschinelles Lernen aus großen Datensätzen, um Inhalte, Kunstwerke, Texte und andere Werke zu generieren, die oft mit menschlichen Leistungen vergleichbar sind oder sie sogar übertreffen. Es ist jedoch wichtig anzuerkennen, dass Daten eine wesentliche Rolle spielen, um diesen außergewöhnlichen Fortschritt voranzutreiben.
Aber warum ist das so? Vielfältige und qualitativ hochwertige Datensätze sind aus mehreren Gründen unerlässlich. Durch eine breite Datenbasis können generative KI-Modelle eine breitere und anpassungsfähigere Palette von Ergebnissen erzeugen. Bei Aufgaben wie der Generierung von Texten, der Synthese von Bildern oder der Komposition von Musik ist dies von entscheidender Bedeutung, da verschiedene Personen unterschiedliche Vorlieben und Bedürfnisse haben können. Durch das Training mit vielfältigen Daten kann die KI den Anforderungen eines breiten Publikums effektiv gerecht werden und vermeiden voreingenommene Ergebnisse zu produzieren.
Die Rolle von Daten beim Einsatz generativer KI
„Damit GenAI effizient und effektiv eingesetzt werden kann, ist eine Vielzahl verschiedener Daten entscheidend.“
Wenn KI-Modelle auf einem eingeschränkten und voreingenommenen Datensatz trainiert werden, können sie unbeabsichtigt voreingenommene oder anstößige Inhalte generieren. Je schlechter die Datenqualität ist, desto höher ist die Wahrscheinlichkeit und das Ausmaß von voreingenommenen Ergebnissen. Die Verwendung vielfältiger und hochwertiger Datensätze trägt dazu bei, diese Voreingenommenheit zu verringern, indem das Modell mit einem breiteren Spektrum an Standpunkten und Erfahrungen vertraut gemacht wird, wodurch es robuster wird.
Kurz gesagt: Um zuverlässige, flexible, moralisch einwandfreie und vielseitige KI-Modelle zu trainieren, die eine Vielzahl von Aufgaben und Eingaben bewältigen können, ist es entscheidend, eine breite Palette erstklassiger Datensätze zur Verfügung zu haben. Dies ist ein wichtiger Faktor, um die Effektivität und verantwortungsvolle Nutzung von KI in verschiedenen Anwendungen sicherzustellen.
Nachdem wir nun die Bedeutung einer breiten Palette von Datensätzen kennen, stellt sich die Frage, wie wir diese Vielfalt erreichen können. Eine Methode, die sich in der Praxis bei uns von PwC bewährt hat, ist der Datenbeschaffungsprozess.
„Datenbeschaffung beschreibt einen datentypabhängigen und standardisierten Prozess zur Erfassung und Bereitstellung von Daten für spätere Analysen und die Weiterverwendung.“
Es ist wichtig zu beachten, dass sich Datenbeschaffung auf Daten bezieht, die über einen Anbieter erworben wurden. Im Gegensatz dazu bezieht sich die Datenintegration auf den Prozess, durch den wir Daten, die PwC bereits besitzt, verfügbar machen. Bei PwC Deutschland hat das Chief Data Office die Service Ownership für die Beschaffung von Drittanbieterdaten mit folgenden Verantwortlichkeiten und Vorteilen:
Verantwortlichkeiten
- Bereitstellung einer zentralen Verwaltungseinheit für eine strukturierte und zentralisierte Datenbeschaffung
- Maximierung des Mehrwerts von Daten, indem die Nutzung vorhandener Datensätze gefördert wird z. B. durch Lizenzerweiterungen
- Festlegung strategischer Anforderungen, die Datensätze erfüllen müssen
Die Vorteile: Ein koordinierter Ansatz zur Datenbeschaffung reduziert Kosten und Risiken
- Kostenersparnis: Die Koordination der Datenbeschaffung reduziert die Anzahl redundanter Datensätze und schafft Transparenz über die aktuelle Verfügbarkeit.
- Sichtbarkeit: Die Rückverfolgbarkeit von Datenquellen und Verbindungen wird durch ein klares Wissen darüber, welche Daten verfügbar sind, gewährleistet.
- Strukturierte Datenbeschaffung: Alle erworbenen Drittanbieterdatensätze müssen einer Überprüfung unterzogen werden, um sicherzustellen, dass strategische Anforderungen (z. B. ein eindeutiger Business Case, Einzigartigkeit, Vereinbarkeit mit der Strategie) erfüllt werden.
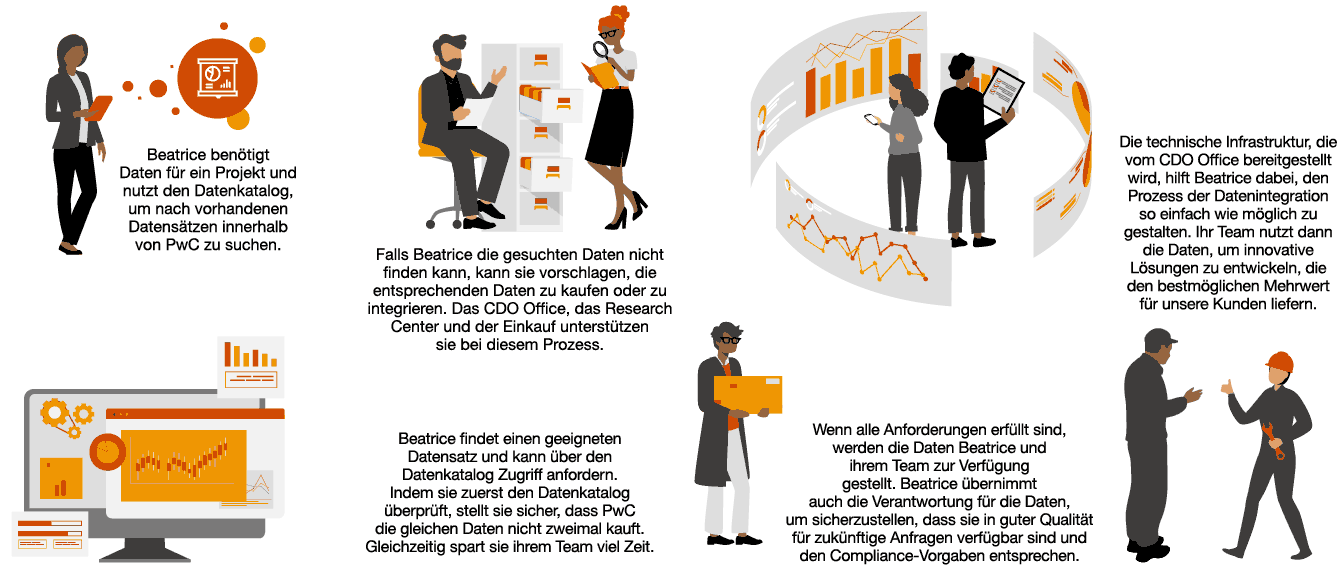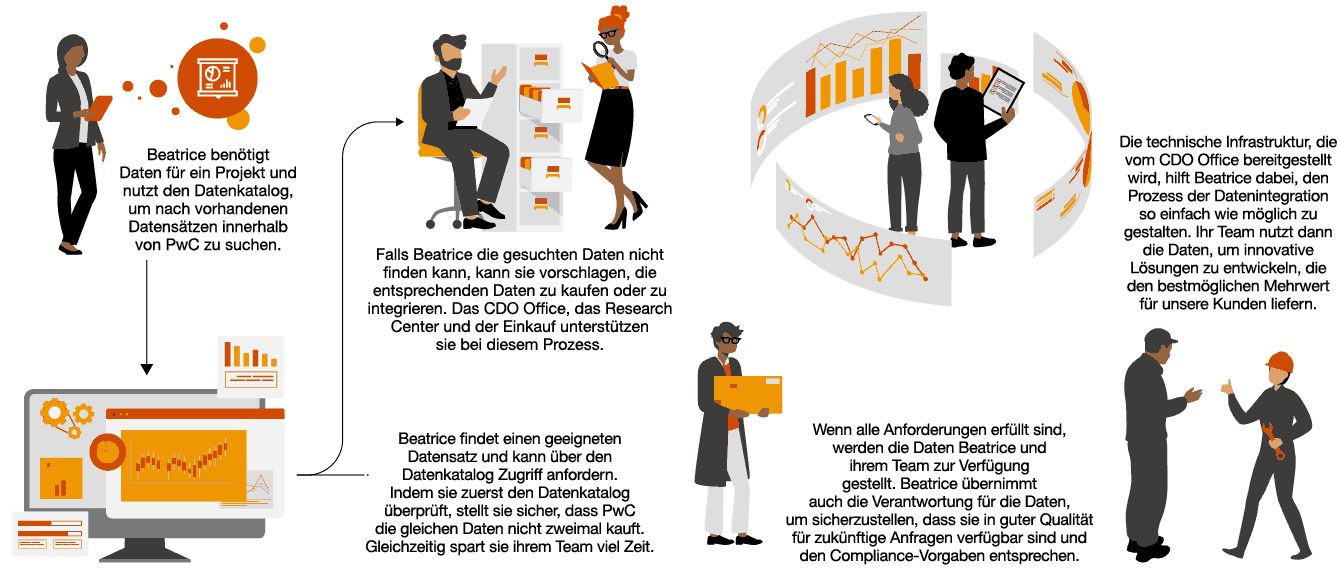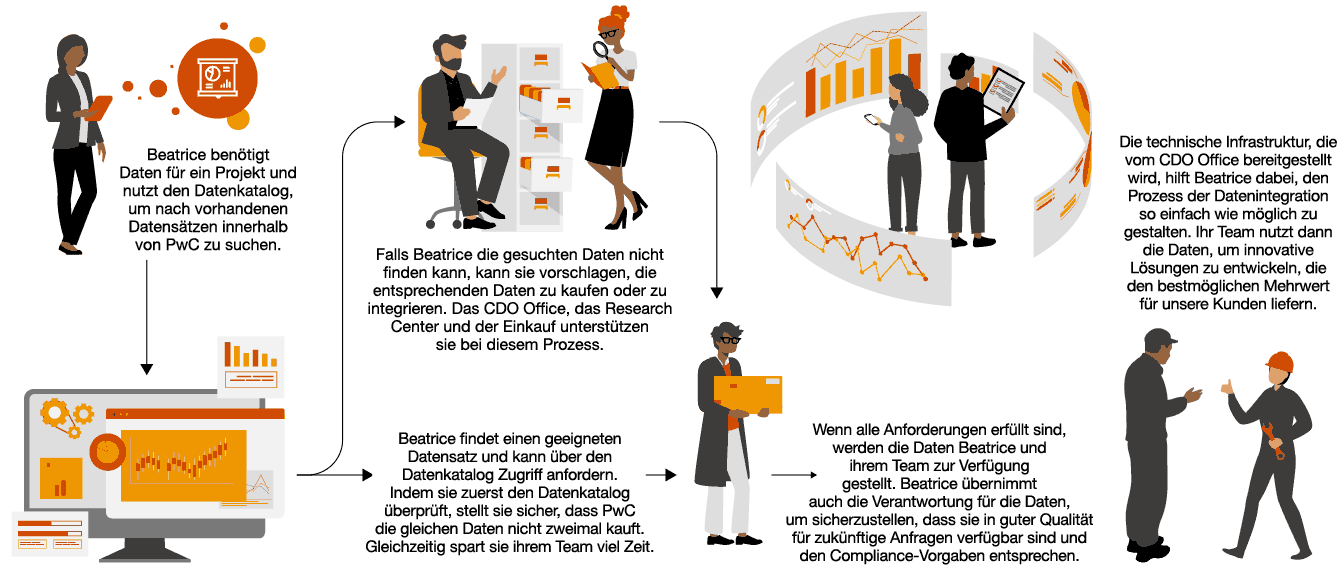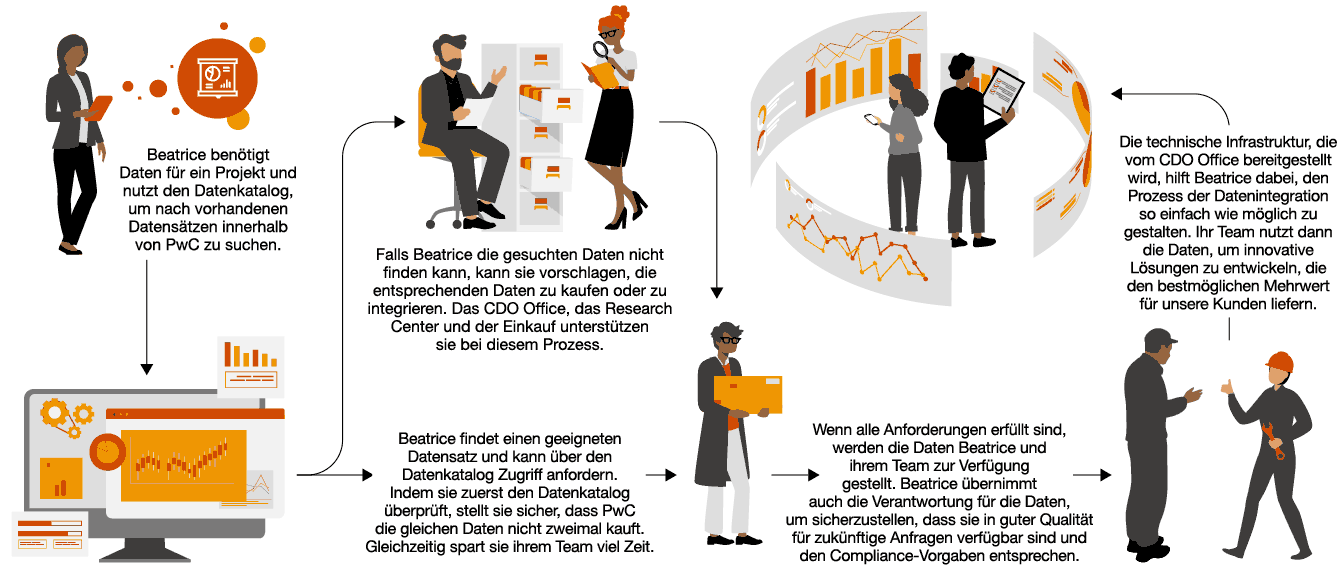
„Richtlinien und Anwendungsfälle müssen definiert werden, um alle Branchen auf ihrer GenAI-Reise zu unterstützen – gestärkt durch ein etabliertes Data Governance Framework.“
Den Datenlebenszyklus verstehen
Es wird einfacher, verschiedene Themen zu verstehen, wenn sie mithilfe eines systematischen Ansatzes erklärt werden. Um den Kontext zu verdeutlichen: PwC orientiert sich in seinen Geschäftsprozessen am Datenlebenszyklus, der ähnlich wie bei einem Produkt verschiedene Stadien durchläuft.
Daten können nicht an einem einzigen Punkt erfasst werden. Ein ganzheitlicher Blick auf den gesamten Lebenszyklus ermöglicht es uns, Daten so zu verwalten, dass sie jederzeit für den jeweils beabsichtigten Zweck zur Verfügung stehen. Der Datenlebenszyklus umfasst den Zeitraum vom ersten Kontakt mit den Daten bei der Generierung bis zum letzten Kontakt, der endgültigen Löschung. Dieser allgemeine Prozess beschreibt den Datenfluss durch eine Organisation. Daten durchlaufen im Datenlebenszyklus verschiedene Punkte.

Erfassen
Bei der Erfassung von Daten kann GenAI verwendet werden, um die erfassten Daten zu ergänzen. Dies bedeutet, dass GenAI die Fähigkeit hat, weitere Beispiele oder Instanzen hinzuzufügen, um den Datensatz zu erweitern und eine robustere Analyse zu ermöglichen. GenAI kann auch hilfreich sein, um eine leicht verständliche Dokumentation für Datenquellen basierend auf spezifischen Metadaten zu erstellen.
Risiko: Durch das Hinzufügen von GenAI in der Datenerfassungsphase steigt das Risiko von Datenverzerrungen, da es existierende Verzerrungen in Ihren Trainingsdaten verstärken und Herausforderungen in Bezug auf den Datenschutz verursachen kann.
Do:
- Datenvielfalt: Es ist entscheidend, eine vielfältige Palette an Daten zu sammeln, um die erfolgreiche Anwendung von generativen KI-Modellen sicherzustellen.
- Daten-Dokumentation: Stellen Sie sicher, dass Sie sorgfältig dokumentieren, wie Sie die Daten gesammelt haben, einschließlich Details zu den Quellen, den Erfassungsmethoden und etwaigen Einwilligungserklärungen.
Don’t:
- Übermäßige Datenerfassung: Achten Sie darauf, keine irrelevanten Daten im Übermaß für Ihr Projekt zu sammeln, da dies möglicherweise zu zusätzlichen Risiken im Bereich Datenschutz und Datensicherheit führt.

Verarbeiten
GenAI kann bei der Verarbeitung von Daten unterstützen, indem es Ihnen bei der Bereinigung der Daten hilft, was zu einer verbesserten Datenqualität und verkürzten Verarbeitungszeiten führt.
Hinweis: Eine Datenqualität von 100 Prozent wird auch mit GenAI nicht erreicht. Für geschäftskritische Anwendungen benötigen Sie immer noch einen Menschen, der die Ergebnisse prüft.
Risiko: Bei der Verarbeitung von Daten, insbesondere bei der Verwendung von Systemen oder Modellen, die nicht Ihnen gehören, ist es wichtig, die Daten zu anonymisieren. Daher können bei der Verwendung von GenAI im Bereich der Datenverarbeitung verschiedene Situationen auftreten, die zu einer unbeabsichtigten Offenlegung von Informationen führen können, wie z. B. übermäßig transparente Modelle oder unzureichende und erfolglose Anonymisierungstechniken. Solche Fälle könnten dazu führen, dass sensible Informationen in unbefugten Besitz gelangen.
Do:
- Datenvalidierung: Überprüfen Sie die Schritte der Datenverarbeitung, um Datenlecks zu verhindern.
- Bewertung der Datenqualität: Überprüfen Sie nach der Verarbeitung regelmäßig die Datenqualität, um die Datenintegrität sicherzustellen.
Don’t:
- Übermäßige Datenmanipulation: Vermeiden Sie übermäßige Datenmanipulation, die die Genauigkeit, Integrität und Qualität der Originaldaten beeinträchtigen könnte. Dies kann durch die Generierung sauberer Daten oder das Ersetzen fehlender oder fehlerhafter Werte erfolgen.

Analysieren
Mithilfe der Datensynthese kann GenAI zusätzliche Datenpunkte für die Analyse bereitstellen oder die Untersuchung hypothetischer Situationen erleichtern, vorausgesetzt, die Daten folgen erkannten Mustern.
Risiko: Wir empfehlen hier vorsichtig vorzugehen, da dies zu Overfitting führen kann, was potenziell Daten erzeugt, die die tatsächlichen zugrunde liegenden Muster nicht genau repräsentieren. Darüber hinaus ist es wichtig sicherzustellen, dass alle generierten Daten angemessen gekennzeichnet oder dokumentiert sind, um Fehlinterpretationen zu vermeiden.
Do:
- Kreuzvalidierung: Verwenden Sie Kreuzvalidierung, um die Qualität und Verallgemeinerbarkeit der generierten Daten zu bewerten.
- Validierungsmetriken: Legen Sie geeignete Validierungsmetriken fest, um die Verlässlichkeit der generierten Daten zu bewerten.
Don’t:
- Übermäßiges Vertrauen: Verlassen Sie sich nicht ausschließlich auf generierte Daten; kombinieren Sie sie für umfassende Analysen mit echten Daten.
„Achten Sie bei jedem Schritt auf Datenhalluzinationen sowie auf Datenschutz- und Datensicherheitsprobleme.“
„Datenhalluzinationen“ sind Situationen, in denen das KI-Modell frei erfundene oder falsche Ergebnisse produziert, oft ohne jeglichen Bezug zu den Trainingsdaten oder der gegebenen Eingabe. Diese Ergebnisse können irreführend, irrelevant oder unsinnig sein. Halluzinationen können aufgrund von Limitationen in den Trainingsdaten oder der Struktur des Modells auftreten und können in Anwendungen, in denen die Genauigkeit und Zuverlässigkeit der Eingabedaten eine große Rolle spielen, wie z. B. der natürlichen Sprachverarbeitung oder der Bildgenerierung, Probleme verursachen. Betrachten wir zum Beispiel ein Textgenerierungstool auf Basis generativer KI. Es könnte halluzinieren, indem es Sätze oder Informationen generiert, die faktisch falsch sind oder in keinen Zusammenhang mit dem Input stehen. Die Vermeidung und Minimierung dieser Halluzinationen bleibt eine fortlaufende Herausforderung bei der Entwicklung von generativen KI-Modellen, da dies entscheidend dafür ist, dass KI-Systeme vertrauenswürdige und zuverlässige Inhalte generieren können – insbesondere in Anwendungen, in denen Genauigkeit und Zuverlässigkeit besonders wichtig sind.

Speichern
Durch die Verwendung von generativen Modellen ist es möglich, bestimmte Datensätze zu komprimieren und so den benötigten Speicherplatz zu reduzieren, ohne dabei wesentliche Merkmale der Daten zu verlieren.
Risiko: Die Möglichkeit, mehr Daten zu speichern, birgt aus Sicht der Datenaufbewahrung zusätzliche Risiken.
Do:
- Richtlinien zur Aufbewahrung von Daten: Implementieren Sie klare und konforme Regeln zur Aufbewahrung von Daten, insbesondere für generierte Daten.
Don’t:
- Unsichere Speicherung: Vermeiden Sie die Speicherung von Daten an unsicheren Orten oder in unsicheren Formaten.

Teilen
In der Phase des Teilens kann GenAI dazu verwendet werden, synthetische oder anonymisierte Versionen der Daten für den Austausch zu erstellen, um die Privatsphäre zu wahren und gleichzeitig Dritten die Verwendung repräsentativer Daten zu ermöglichen.
Risiko: Das Teilen sensibler Informationen, auch wenn sie angemessen anonymisiert sind, kann potenziell zu Verletzungen der Privatsphäre oder unbefugter Nutzung für ungewollte Zwecke führen.
Do:
- Einwilligungen und Vereinbarungen: Stellen Sie sicher, dass der Datenaustausch den Einwilligungen, Vereinbarungen und rechtlichen Anforderungen entspricht.
- Datenminimierung: Teilen Sie nur die notwendigen Daten und halten Sie sie so minimal wie möglich.
Don’t:
- Unkontrolliertes Teilen: Vermeiden Sie das Teilen von Daten ohne angemessene Einwilligungen, Vereinbarungen und Kontrollmechanismen.

Archivieren
In Bezug auf die Archivierung von Daten kann GenAI Ihnen auf die zuvor genannten Arten helfen, wie z. B. durch das Zusammenfassen, Komprimieren oder Analysieren von archivierten Daten. Darüber hinaus kann GenAI Sie bei der Kategorisierung und Organisation von gespeicherten Informationen unterstützen. Durch das Training von Modellen zur Identifizierung von Mustern und Inhalten in den Daten kann GenAI automatisch relevante Schlüsselwörter oder Labels zuweisen, um die einfache Suche und Wiederherstellung von archivierten Informationen zu erleichtern.
Risiko: Wenn der Prozess nicht sorgfältig kontrolliert wird, kann GenAI archivierte Daten unbeabsichtigt verändern oder verzerren, was zu Datenverlust oder einer Verschlechterung der Datenqualität führen kann.
Do:
- Datenkonservierung: Nutzen Sie GenAI, um die Datenkonservierung zu verbessern, indem Sie Duplikate erstellen, beschädigte Daten wiederherstellen und sicherstellen, dass die Daten in zukünftigen Formaten oder Systemen zugänglich sind.
- Datenkompression: Nutzen Sie GenAI, um den Speicherbedarf durch Kompressionstechniken zu reduzieren, die die Genauigkeit der Informationen beibehalten.
- Datenumwandlung: Setzen Sie GenAI ein, um Daten in standardisierte, offene oder langfristig erhaltbare Formate umzuwandeln, um die zukünftige Kompatibilität zu gewährleisten.
- Regelmäßige Qualitätsbewertung: Bewerten Sie regelmäßig die Qualität der gespeicherten Daten mithilfe von GenAI, um Verschlechterungen oder Unregelmäßigkeiten zu identifizieren.
- Datenzusammenfassung: Nutzen Sie GenAI, um kurze Zusammenfassungen oder Übersichten der gespeicherten Daten zu generieren und so deren Nutzbarkeit zu verbessern.
Don’t:
- Vernachlässigung von Datenlecks: Stellen Sie sicher, dass die in der Archivierung verwendeten GenAI-Modelle ordnungsgemäß konfiguriert sind, um Datenlecks oder die Offenlegung sensibler Informationen zu verhindern.
- Fehlende Datenwiederherstellungsmaßnahmen: Verlassen Sie sich nicht ausschließlich auf GenAI zur Wiederherstellung von Daten. Setzen Sie auch auf zusätzliche Backup- und Wiederherstellungstaktiken.

Löschen
GenAI kann bestimmen, welche Daten gelöscht werden sollten, wann sie gelöscht werden sollten und aus welchen Gründen (z.B. aufgrund spezifischer Richtlinien). In Fällen, in denen sensible Daten gelöscht werden müssen, kann GenAI Ersatzinformationen erzeugen, um die Integrität von Datenbanken und Anwendungen, die von den gelöschten Daten abhängen, zu erhalten.
Risiko: Bei der Verwendung von GenAI im Datenlöschungsprozess können Rückstände verbleiben, sodass die Daten von unerwünschten Parteien abgerufen werden können. Wenn die Anwendung nicht ordnungsgemäß konfiguriert ist, kann sie auch Daten löschen, die nicht gelöscht werden sollten und damit unwiederbringlich verloren sind.
Do:
- Sichere Löschtechniken: Gewährleisten Sie die Sicherheit sensibler Informationen, indem Sie sichere Techniken zur Datenlöschung verwenden, wie z. B. Überschreiben oder kryptografische Löschung, um eine mögliche Wiederherstellung zu verhindern.
- Abhängigkeitsanalyse: Untersuchen Sie vor der Durchführung von Löschvorgängen sorgfältig Datenabhängigkeiten in Systemen und Anwendungen, um mögliche Konsequenzen zu identifizieren.
- Datenersatz: Verwenden Sie GenAI bei Bedarf, um Ersatzdaten zu generieren und die Struktur und Funktionalität von Systemen, die von gelöschten Daten abhängen, aufrechtzuerhalten.
Don’t:
- Unvollständige Löschung: Vermeiden Sie unvollständige oder unsichere Methoden zur Datenlöschung, bei denen Datenrückstände zurückbleiben.
- Eilige Löschung: Nehmen Sie sich Zeit bei der Datenlöschung; Eile kann zu Fehlern führen. Prüfen Sie Abhängigkeiten sorgfältig und gewährleisten Sie einen sicheren Löschvorgang.
- Datenlöschung ohne Backup: Löschen Sie keine Daten, ohne ein ordnungsgemäßes Backup oder einen Plan zur Datenwiederherstellung zu haben, insbesondere wenn es sich um kritische oder unersetzliche Daten handelt.
- Löschung ohne Dokumentation: Dokumentieren Sie immer den gesamten Prozess der Datenlöschung, einschließlich der Gründe für die Löschung und aller durchgeführten Maßnahmen.
Zusammenfassung
Daten spielen eine bedeutende Rolle im Bereich der Generativen KI und sind einer ihrer grundlegenden Komponenten. Im gesamten Datenlebenszyklus gibt es umfangreiche Möglichkeiten für GenAI, um zur Steigerung der Effizienz beizutragen.
„Stellen Sie eine umfassende Integration zwischen Unternehmensstrategie und Datenstrategie sicher.“
Es wird für Unternehmen immer wichtiger, eine solide Grundlage im Datenmanagement zu schaffen und eine Kultur zu fördern, die Daten sowohl auf Ebene der Mitarbeitenden als auch auf Management-Ebene wertschätzt. Dies muss in die übergreifenden Ziele des Unternehmens integriert und dann in eine Datenstrategie übersetzt und in den operativen Strukturen umgesetzt werden.
Das Management spielt eine entscheidende Rolle bei der Entwicklung von Richtlinien, die diese Aspekte umfassen und bei der Förderung einer Umgebung, die sich auf Daten konzentriert. Ohne eine angemessene Data Governance, Richtlinien und eine grundlegende Datenkompetenz besteht die Gefahr, dass generative KI Risiken birgt, die so weit wie möglich reduziert werden müssen.
„Immer wenn Daten bei PwC verwendet werden, gibt es einen oder mehrere Schritte in der Datenwertschöpfungskette, die helfen können, effizienter zu arbeiten. Während die Ideenfindung und das Produktmanagement bei Ihnen bleiben, ermöglicht das CDO Office die Prozesse, die die Wertschöpfung vorantreiben. Das Data & Content Team des CDO stellt die grundlegende Struktur sowohl für die technische Umsetzung als auch für die Steuerung und operativen Fähigkeiten wie einen Datenkatalog und ein Datenökosystem bereit. Das Data & Tech Team baut die Infrastruktur auf, die allen Operationen zugrunde liegt. Schließlich vervollständigen verschiedene Ebenen der Compliance und des Risikos das Bild, bei dem Ihnen der CDO helfen kann.“
PwC verfügt über internes und externes Wissen sowie modernste Ressourcen im Bereich Daten, die effizient genutzt werden können, um das immense Potenzial von GenAI auszuschöpfen. Wenn Sie Hilfe oder Unterstützung zu diesem Thema benötigen, zögern Sie nicht, sich an unser Team kompetenter Spezialist:innen zu wenden, die Ihnen jederzeit gerne zur Verfügung stehen.
Unsere Webcast-Reihe
GenAI – What decision-makers need to know now



Contact us



Christine Flath
Leitungsteam Familienunternehmen und Mittelstand und Ihre Ansprechpartnerin für Transformationsthemen, PwC Germany
Tel.: +49 171 5666490



